
Self-Healing Ingress: A Gateway That Diagnoses, Fixes, and Explains Itself
Kubernetes self-heals by reflex: it restarts what crashes. But a reflex isn't judgment — a crash-looping pod gets restarted straight back into the same failure, and the gateway never asks why. This talk walks through an ingress architecture that adds judgment on top of Envoy and Istio. It correlates Envoy stats, OpenTelemetry traces, and Kubernetes events into ranked root-cause hypotheses, scores candidate fixes on reversibility and blast radius, acts inside concentric guardrail rings, and verifies against success criteria declared before it acts. The real differentiator isn't the automation — it's that every action ships with a human-readable decision record, because in regulated systems remediation that can't explain itself can't run in production. You'll leave with a failure taxonomy for the ingress layer and a blast-radius model you can apply to your own controllers. Benefit to cloud native ecosystem (391 chars): Operators lean on Kubernetes' built-in healing, but blind restarts mask root causes and can amplify outages. This talk gives the community a concrete pattern for safe, interpretable auto-remediation on Envoy, Istio, and OpenTelemetry — a failure taxonomy, a five-dimension risk model, and guardrail rings that let teams adopt autonomy incrementally without betting production on a black box.
TL;DR — Kubernetes already "self-heals": it restarts what crashes. Those are reflexes, not judgment. This article walks through the architecture of a self-healing ingress layer designed for payments-grade infrastructure: a decision pipeline that converts telemetry into ranked root-cause hypotheses, scores candidate remediations on risk and reversibility, executes inside hard blast-radius guardrails, verifies outcomes against pre-declared success criteria, and rolls itself back when it's wrong. The differentiator is not the automation — it's that every action ships with a human-readable decision record. In regulated environments, remediation that can't explain itself can't run in production.
03:17 — The Anatomy of an Ingress Incident
The page lands at 03:17. p99 latency on the payments path has tripled and 5xx rates are climbing. You acknowledge from your phone, open the laptop, and begin the ritual I call dashboard archaeology: Envoy cluster stats, Istio control-plane metrics, Kubernetes events, last night's deploy log, the certificate-rotation calendar. Fifteen minutes in, you find it — a canary build is OOMKilling on one node pool, the gateway's outlier detection has been ejecting endpoints, and retries are quietly amplifying load on the survivors.
Here's the uncomfortable part: the cluster was "self-healing" the entire time. The kubelet dutifully restarted every OOMKilled pod. Each one came back, passed its liveness probe, accepted traffic, and died again. Kubernetes did exactly what it was built to do. It just had no concept of why anything was failing, and therefore no way to choose an action that would actually help.
That gap — between reflex and judgment — is what this article is about. What follows is the architecture of a self-healing ingress prototype we built as an internal hackathon project, informed by years of operating a high-throughput payments ingress. The healing mechanics turned out to be the easy part. The hard parts were deciding which action to take, bounding the damage when the decision is wrong, and producing an explanation a human — or an auditor — can trust.
Why Incidents Concentrate at the Ingress Layer
The ingress tier is the convergence point of your most dangerous configuration: TLS termination, authentication, routing rules, retry policies, rate limits, connection pooling, canary weights. Measured in blast radius per line of YAML, nothing else in the stack comes close. Google's SRE book famously attributes the majority of outages to changes in live systems — and the gateway is where changes from every team in the company physically intersect.
In practice, ingress failures cluster into three classes:
Control-plane and configuration failures. A bad route push, an expired certificate, xDS drift between what the control plane intends and what Envoy is actually running. These are change-induced, often instantaneous, and global in scope.
Data-plane capacity failures. Connection-pool exhaustion, listener saturation, retry storms. These build gradually and then cliff. The cruel detail is that the gateway's own resilience features are frequently the accelerant: retries multiply load on a degraded upstream at exactly the moment it can least absorb it.
Dependency-reflected failures. Unhealthy upstream hosts, stale endpoints during heavy pod churn, a degraded availability zone. The upstream is sick, but the gateway is where the sickness becomes customer-visible — so the gateway is what gets blamed, paged on, and ultimately must respond.
A remediation system has to distinguish these classes, because the correct action for one is actively harmful for another. Scaling out replicas fixes a capacity problem and does nothing for a bad config push. Rolling back configuration fixes the push and does nothing for a memory leak. Blindly restarting pods fixes neither and can make all three worse.
Why "Just Restart It" Is Dangerous in Payments
Most generic auto-remediation advice quietly assumes workloads are stateless and requests are free. Payments traffic violates both assumptions.
In-flight requests are not free. A pod restart drops every request it is holding. In a payments flow, a request dropped after the debit side commits but before the response returns produces the worst possible customer experience: an error message for a transaction that succeeded. The client retries, and now you are betting the customer's balance on idempotency keys being honored at every layer between the mobile app and the ledger. Most stacks honor them at most layers. "Most" is not a payments word.
Retries are a loaded weapon. Envoy's retry budgets exist because naive retry policy converts a partial degradation into a total one. An auto-remediator that responds to elevated errors by loosening retry or timeout policy is pouring fuel on the fire with perfect confidence. Any action catalog has to model second-order traffic effects, not just first-order symptom relief.
Remediation can race your deployment pipeline. Roll back gateway configuration while your CD system is mid-canary and you get config split-brain: two control loops fighting over the same VirtualService, each interpreting the other's correction as new drift. A remediation system must coordinate with the deploy system — a lock, or at minimum detection of in-progress rollouts with an automatic stand-down.
The conclusion we kept arriving at: in this domain, which action you take — and whether it preserves in-flight work — matters far more than how fast you take it. Speed without judgment is just faster damage.
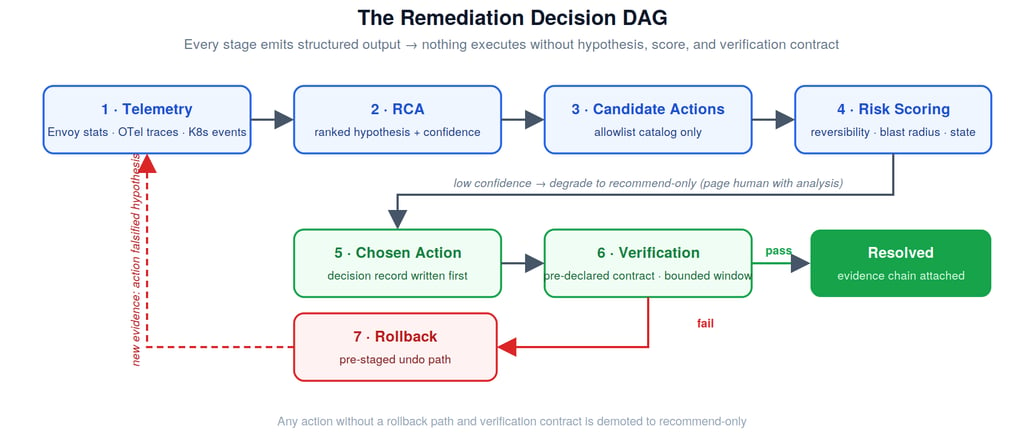
The Architecture: A Decision DAG, Not a Reflex Arc
Naive automation is a trigger-action pair: if 5xx > threshold then restart. Our prototype models remediation as a directed acyclic graph of decisions instead:
Telemetry → RCA → Candidate Actions → Risk Scoring → Chosen Action → Verification → (Resolve | Rollback)
Every stage emits structured output that feeds both the next stage and the decision record (more on that record later — it's the whole point). Nothing executes until the pipeline has produced a hypothesis, a ranked action list, a risk score, and a pre-declared verification contract. If any stage can't meet its bar, the system degrades gracefully to recommend-only mode: it pages a human with its analysis attached instead of acting.
Stages 1–2: From Signals to Hypotheses
The telemetry stage consumes three streams: Envoy/Istio stats, OpenTelemetry traces, and Kubernetes events. Individually, each stream is ambiguous. Correlated, they discriminate between failure classes surprisingly well:
SignalSourceTypical hypothesisupstream_rq_5xx spike, connection counts stableEnvoy cluster statsUpstream application regression, not networkupstream_cx_pool_overflow + rising p99Envoy circuit breakersConnection-pool exhaustion / capacityoutlier_detection.ejections_active climbingEnvoy outlier detectionUnhealthy subset of upstream hostsupstream_rq_retry_overflowEnvoy retry budgetRetry storm in progressxDS NACKs / failed config pushesIstiod (pilot) metricsBad route or listener config pushEndpoint churn + readiness flapsKubernetes eventsCrash-looping or OOMKilled upstreamsp99 latency attributed to the ingress hopOpenTelemetry span analysisGateway-local problem: TLS, filters, buffering
The trace stream deserves a special mention. Span-level latency attribution answers the single most triage-accelerating question in any ingress incident: is the time being spent at the gateway hop or the upstream hop? That one bit of information eliminates half the hypothesis space before any human would have finished logging in.
The RCA stage's job is not certainty — it is a ranked hypothesis with a confidence score, assembled from signal correlation plus similarity search against an incident knowledge base of past, labeled events. That confidence number is not decorative: it directly gates what the system is permitted to do downstream. Low confidence collapses the pipeline into recommend-only mode. We found this single design rule eliminated the scariest failure mode of autonomous remediation — confidently doing the wrong thing.
Stages 3–4: Candidate Actions and Risk Scoring
The action catalog is a deliberately small allowlist. Ours: shift traffic weights (VirtualService), roll back gateway config to last-known-good, scale replicas, eject or restore specific upstream hosts, tighten a circuit breaker, drain-then-restart a workload, and fail traffic away from a zone. Nothing outside the catalog is executable, period. An autonomous system with an open-ended action space is not an SRE tool; it's an incident generator with API access.
Each candidate action is scored across five dimensions:
Reversibility — can the action be cleanly undone? A traffic shift reverses in seconds; a pod restart cannot be un-restarted.
State sensitivity — does the action drop in-flight requests? This is the payments-specific veto dimension.
Blast radius — endpoint, service, cluster, or zone scope.
Hypothesis confidence — how sure are we that this action addresses the cause rather than the symptom?
Historical efficacy — how often has this action class resolved this hypothesis class before, per the knowledge base?
Scores then map onto concentric guardrail rings, each with a hard gate:
Ring 0 — Observe & recommend. Always available. The floor, never the ceiling.
Ring 1 — Reversible, request-preserving actions. Traffic shifts, scale-out, config rollback to a verified last-known-good. Available at moderate confidence.
Ring 2 — Disruptive single-workload actions. Drain-then-restart, host ejection. Requires high confidence and a connection-drain check proving no in-flight payments will be dropped.
Ring 3 — Cluster- or zone-scoped actions. Never autonomous. The system prepares the full runbook, pre-stages the commands, and pages a human to approve. Its job at this ring is to make the human decision take thirty seconds instead of thirty minutes.
The asymmetry is intentional. The cost of under-acting is a slower fix; the cost of over-acting in a payments system is measured in duplicated transactions and regulator phone calls. We bias accordingly.
Stages 5–7: Execute, Verify, Roll Back
The most underrated rule in the whole design: verification criteria are declared before execution, not after. The chosen action ships with a contract — for example, "upstream_rq_5xx < 1/s and zero new ejections, sustained for 10 minutes." A bounded observation window watches the contract. Pass, and the incident resolves with the full evidence chain attached. Fail, and the system executes the action's pre-staged rollback and re-enters the RCA stage with one more piece of evidence: the thing we tried didn't work — which is itself diagnostically valuable, because it falsifies the leading hypothesis.
Declaring criteria up front kills two classic automation pathologies at once. It prevents goalpost-moving ("error rate is still elevated but trending better, let's call it fixed"), and it forces the uncomfortable design question early: if this action has no rollback path, why is it in the autonomous catalog at all? Any action that can't define both a contract and a rollback is demoted to Ring 0 — recommend-only.
In our prototype runs on injected Ring-1 failures (bad canary, pool exhaustion, retry storm), the autonomous loop consistently collapsed the detect → triage → mitigate phases — the part of every incident dominated by paging a human and waiting for context-loading — while spending more time than a hurried human typically does on the verification window. That trade is exactly backwards from how humans behave at 3 AM, and exactly right.
The Real Differentiator: Remediation That Explains Itself
Everything above is solid engineering, but none of it is why I'd argue this architecture matters. Plenty of teams can wire telemetry to actions. The differentiator is that every decision the system makes is captured in a structured, human-readable decision record — produced before execution, immutable after.
Here's a representative record from a prototype run:
json
{ "incident_id": "ing-2026-0412-0317", "detected_at": "2026-04-12T03:17:42Z", "evidence": [ "envoy.cluster.payments-core.upstream_rq_5xx rate 14.2/s (baseline 0.3/s)", "outlier_detection.ejections_active = 3 of 24 endpoints", "trace latency attribution: 91% of p99 at upstream hop", "k8s: 3 pods OOMKilled in payments-core, node pool m5-2xl-c" ], "hypothesis": { "cause": "memory regression in payments-core canary v2.41.3 causing OOM kills on a node subset", "confidence": 0.84 }, "candidate_actions": [ {"action": "shift_canary_weight", "params": {"v2.41.3": 0, "v2.41.2": 100}, "risk": 0.12, "reversible": true, "drops_inflight": false}, {"action": "scale_replicas", "delta": "+4", "risk": 0.22, "reversible": true, "drops_inflight": false}, {"action": "restart_pods", "scope": "3 ejected endpoints", "risk": 0.31, "reversible": false, "drops_inflight": true} ], "chosen_action": "shift_canary_weight", "rationale": "Highest-confidence cause isolates to the canary version; traffic shift is fully reversible, preserves all in-flight requests, and does not mask the underlying defect.", "verification": { "criteria": "upstream_rq_5xx < 1/s AND zero new ejections, sustained 10m", "result": "passed at 03:29:08Z", "rollback_triggered": false } }
From that structured record, the system renders a natural-language explanation for non-engineers:
At 03:17, error rates on the payments-core service rose ~47× baseline. Evidence pointed to the v2.41.3 canary exhausting memory on a subset of nodes. The system shifted canary traffic back to v2.41.2 — a fully reversible action that preserved all in-flight requests — and confirmed recovery within 12 minutes. No human was paged. The defect was routed to the owning team with the complete evidence chain attached.
One implementation detail that matters more than it looks: the narrative is template-rendered from the structured fields, not free-generated. If you let a language model freely compose the explanation, you eventually get a beautifully written rationale that doesn't match what the system actually did — a hallucinated audit trail, which is worse than no audit trail. Grounded generation only. The record is the source of truth; the prose is a projection of it.
Why obsess over this? Because in regulated infrastructure, the question after any automated action is never just "did it work?" It is "who decided, based on what evidence, considering what alternatives, with what authority?" Change-management reviews ask it. Auditors ask it. Your own postmortems ask it. A remediation system that answers those questions by design clears the production bar; one that answers "the model decided" does not. My one-line test for any autonomous infrastructure system: if your remediation can't survive an audit, it can't run in production. An auto-remediation system that can't explain itself is just an outage with extra steps.
There's a quieter benefit, too. The decision records accumulate into a labeled corpus — evidence, hypothesis, action, outcome — that compounds: every verified resolution sharpens the historical-efficacy scores, and every failed verification prunes a bad hypothesis-action pairing. The system gets better at judgment the same way senior SREs do: by remembering what actually worked.
What This Doesn't Solve (Yet)
Honesty section, because vendor-grade overclaiming is how this space loses credibility:
RCA confidence is the load-bearing weakness. Signal correlation handles the common failure classes well; genuinely novel failures produce low-confidence hypotheses, and the system correctly collapses to recommend-only — which means the hardest incidents still belong to humans. That's the right behavior, but it caps the autonomy ceiling.
The action catalog is deliberately tiny. Every addition needs a rollback path, a verification contract, and a state-sensitivity analysis. The catalog grows at the speed of trust, not the speed of ambition.
It heals the control plane, not the data plane. The system manipulates routing, scaling, and configuration. It does not patch a memory leak — it contains the blast and hands the defect, with its evidence chain, to the owning team.
Verification windows cost minutes. A ten-minute contract on a Ring-1 action is sometimes slower than a cowboy fix. We consider that a feature. Not everyone will.
Reflexes Below, Judgment Above
Kubernetes gave us reflexes: restart what crashes, replace what disappears, route around what fails probes. Reflexes are necessary and nowhere near sufficient — every operator of a high-throughput gateway has watched a cluster reflexively restart its way through an incident it had no hope of understanding.
The next layer up is judgment: form a hypothesis, weigh actions against their blast radius, act inside guardrails, verify against a contract you declared in advance, and — above all — leave behind an explanation a human can interrogate. The mechanics of self-healing are the easy 80%. The interpretability is the 20% that determines whether the system is allowed to exist in production at all.
Build the reflexes. Then earn the judgment — one ring at a time.
If you're working on autonomous remediation, interpretable infrastructure, or payments-grade reliability, I'd genuinely like to compare notes — find me on LinkedIn or drop a comment below.